- AI Minds Newsletter
- Posts
- AI Minds #6: The (Real) Cost of Running AI...
AI Minds #6: The (Real) Cost of Running AI...
For businesses, users, and mother nature. From cash burning to carbon emissions, what does AI truly cost?
Jose Nicholas Francisco & Marcel Santilli
October 17, 2023
Welcome (back) to AI Minds, a newsletter about the brainy and sometimes zany world of AI, brought to you by the Deepgram editorial team.
In each edition, we’ll highlight a special topic from the rapidly-evolving field of Language AI. We’ll also touch on timely issues the AI community is buzzing about. As a heads-up, you might want to brace yourself for the occasional spicy take or two along the way. 🌶️
Thanks for letting us crash your inbox; let’s party. 🎉
Introducting Nova-2: The Fastest, Most Accurate Speech-to-Text API
💸 AI and money: Who has the lion’s share?

As developers, researchers, investors, and tech-founders all around the world know, AI isn't cheap. But what makes AI so expensive? Who really ends up making the big bucks? And do small startups really stand a chance against tech giants? Let's learn together, and delve into the intersection of dollar bills and machine learning.
💰 Github and Money: Is anyone really profiting?
Last week we mentioned how Github announced it was making 100m in revenue from its copilot product. At the same time the Wall Street Journal reported Github was losing $20 per copilot user.
The cost of running AI is becoming an issue, even in domains where people are prepared to pay for it:
"Report: GitHub Copilot Loses an Average of $20 Per User Per Month"
— The_AI_Skeptic (@The_AI_Skeptic)
11:54 AM • Oct 10, 2023
The drama continued as the former CEO of Github Nat Friedman dismissed the accusations with one word: FALSE.
The Twittershpere (Xsphere?) blew up with every armchair quarterback CFO voicing their opinion on the topic.
So which one is it, a major success for a generative AI product, the typical Silicon Valley growth at all costs, or both?
One thing is sure, the cost of inference for these big models is not something that can be easily overlooked. Github, a company that has virtually unlimited GPU resources from its parent company Microsoft, and unlimited communication with its “sibling” company OpenAI. If they can’t make the numbers work, how can the rest of us expect to?
Well, if we may briefly offer some advice as an AI company ourselves, here's an article on what founders of AI companies need to know before hopping into the pool.
"We know many investors have their eyes on AI. There have been some big bets on AI up to this point. Would be curious to know the largest number you’ve seen. So, how do you secure a golden ticket of funding? Know your vision and know it well. Investors aren’t just buying into your tech; they’re buying into your dream."

🪙 Are GPUs the gold bars of tech?
🎮 Linear Algebra: The cornerstone of video games and AI
Of all the things to know about AI engineering, there exists one inescapable truth: Artificial Intelligence relies extremely heavily on linear algebra. In language processing, for example, every possible human word (and even fractions of words) are represented as vectors, the cornerstone of linear algebra. Images and audios can be represented as vectors as well. Long story short, linear algebra provides a much more robust, more dynamic way of representing words than this:

This binary representation of the word “dog” is not enough to fully encapsulate the full, nuanced meaning of the concept of a dog. We need vectors.
And that's why GPUs are so important.
GPUs, or graphics processing units, are processors designed specifically for—wait for it—video games. It's a strange fact when you first encounter it. After all, it's not exactly intuitive as to why we use video game technology to run AI models like ChatGPT and StableDiffusion. However, the reason is quite simple: Both video game graphics and artificial intelligence require heavy amounts of linear algebra.
And so, to understand the cost of AI, we must understand the cost of GPUs. In this article by Nithanth Ram, we learn that there is indeed an "acute shortage of GPUs" which has triggered a price surge in the market. Specifically, an individual H100 with memory and a high-speed interface originally retailed for around $33,000. Second-hand units now cost between $40,000 and $51,000.

🐟 GPUs and the cost of scaling
And in the MLOps Community, Aishwarya Goel analyzed how cost increases as your company grows. Specifically, she compares the GPU inference costs between open-source and closed-source models as an application scales from 1k daily active users (DAUs) to 20k DAUs.
It turns out that “deploying fine-tuned open-source models on serverless infrastructure leads to 89% cost reduction compared to open source platforms.”

Deploying fine-tuned, open-source models on serverless infrastructure leads to 89% cost reduction compared to open source platforms.
So to answer the title of this section: Yes, GPUs are indeed the gold bars of tech. Without a GPU, it’s nearly impossible to train, fine-tune, and deploy an AI model at scale. There is no software without first a hardware that can handle it. And with a behemoth like AI, GPUs are the (relatively pricey) hardware for the job.
🏦 The Startups vs. Big Businesses Dilemma
In the middle of this AI gold-mine, some big-name players rush in with billions of dollars already sitting in their pockets. Meanwhile, those in the startup community remain new to having multiple commas in their bank accounts. What does this mean for AI innovation? Who truly is well-positioned to succeed?
Surprisingly, it’s not so clear.
🏡 Hit an API or do it in house?
The beauty of LLMs is that now, off-the-shelf models can be generalized and get you pretty far. However a big question for companies has been the return-on-investment (ROI) of using AI. Does that extra 2% better net you a positive ROI? How can you know?
There are pains of using hosted language model APIs—such as the OpenAI rate-limit, or being subject to model updates that destroy your prompt’s efficiency.
So what do you do? Bring it in-house?
A paper out of Oregon State talks about how in house model development and deployment is a level of luxury only certain companies can afford. With the cost of hardware, energy, and researchers salaries it's no wonder Meta and its fleet of 21.5k A100s are the main ones releasing open source LLMs.
Meanwhile, individual developers doing pet-projects at home, participating in a hackathon, or trying to create their next startup may have to rely on buying used cards. No kidding. That’s legitimate advice from PhD student Tim Dettmers in the 2020 mid-pandemic version of his blog (see citation [14] in the paper). Note that prices have almost universally risen since this advice was given:
“Buy used cards. Hierarchy: RTX 2070 ($400), RTX 2060, ($300), GTX 1070 ($220), GTX 1070 Ti ($230), GTX 1650 Super ($190), GTX 980 Ti (6GB $150)”
Nevertheless, if you’re a soon-to-be founder or an early founder in the AI startup community, fret not. With the market becoming more and more bullish on AI, there indeed remains hope for the little guy. In an analysis from The Boston University School of Law, we learn that “broad distribution [of AI] across industries suggests that the startup environment is healthy, and many opportunities for entry exist. However, some industries may have relatively higher entry barriers than others.”
And sure enough, when we stratify by industry, we can see that investment in startups is quite healthy—although it’s healthier in some industries than others:

And don’t think it’s automatically so easy for the big guys to compete. In the world of automated speech recognition, for example, startups are able to deploy less-expensive models at scale that outperform those of giants like Google, Amazon, and OpenAI.
Just look at the image below to see how expensive OpenAI’s Whisper can be for businesses. Meanwhile, startups are already offering on-prem alternatives for a much, much lower price.
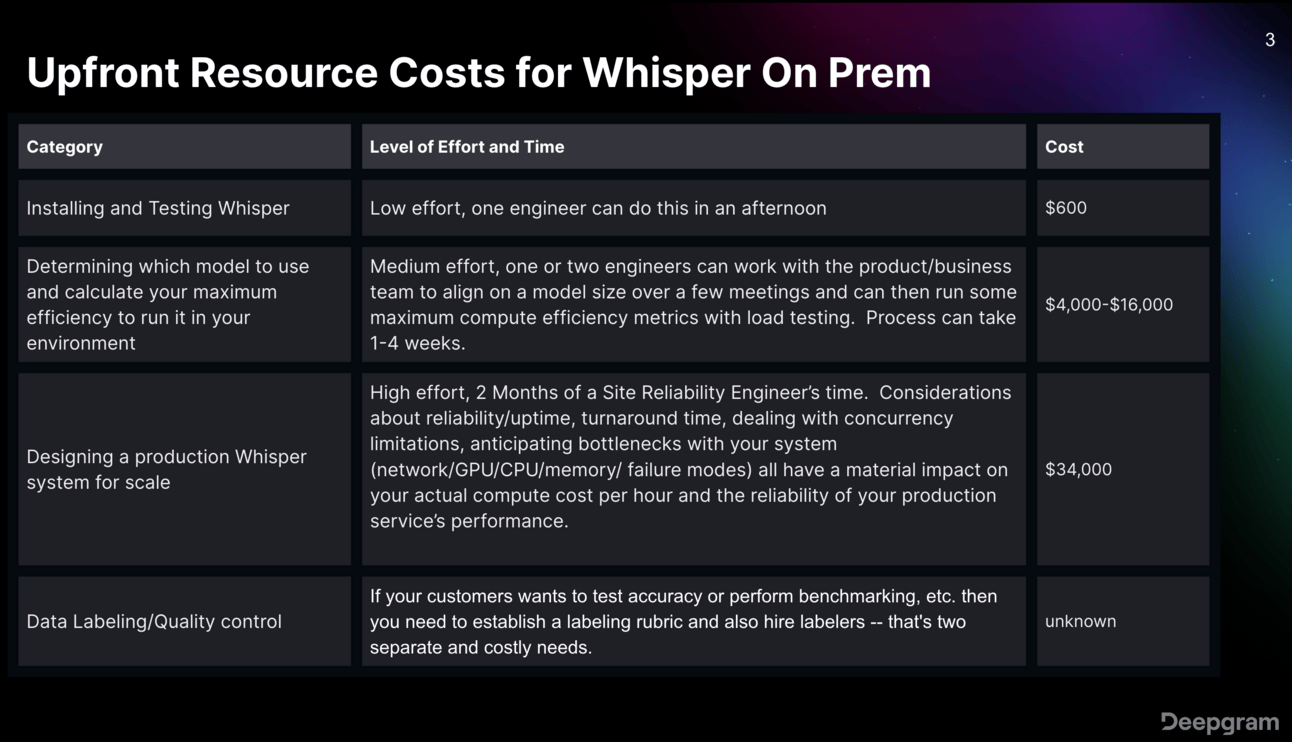
And this graphic doesn’t even include the cost of annualized compute that your company will have to spend, alongside the price of hiring a full-time Site Reliability Engineer ($150k-$200k, annually).
So here’s the punchline: Yes, big-tech companies have heavy monetary advantages. That’s what having loads of money will do. However, the world of AI isn’t owned by MANGA alone. Nor OpenAI alone. Startups with useful (not just clever) ideas and product-market fit can quite easily catch the eyes of investors. And those investors give startups just enough money to create technology that makes big-tech do a double-take.
Startups don’t need Google-level amounts of money to deploy cutting-edge AI at scale. They just need a few investors and a top-notch engineering+research team.
🌿 Money doesn't grow on trees: The Environmental Cost of AI
Beyond money, it’s now time for us to talk about the other green: The environment.
🌲The environmental cost of inference
First thing’s first: How much energy does it take to run an AI? Well, the Oregon State University paper mentioned above mentions that, on an individual level, it depends on your GPU+CPU setup. The graphic below delves into further detail. Click on it to see the full paper.

“Recommended power supply wattage for different CPU+GPU combinations.” (Source: Johnathan Dodge, Orgeon State University)
However, that’s merely the amount of energy used once you have an AI ready-to-go. The bigger question is this: How much energy does it take to train a model in the first place? Do Large Language Models come with large environmental costs?
Researchers from University of Massachusetts Amherst reveal the amount of kiloWatt hours needed to train language models from BERT to GPT, alongside the amount of carbon dioxide (and carbon dioxide equivalent) emitted. Click on the image to read the full paper.
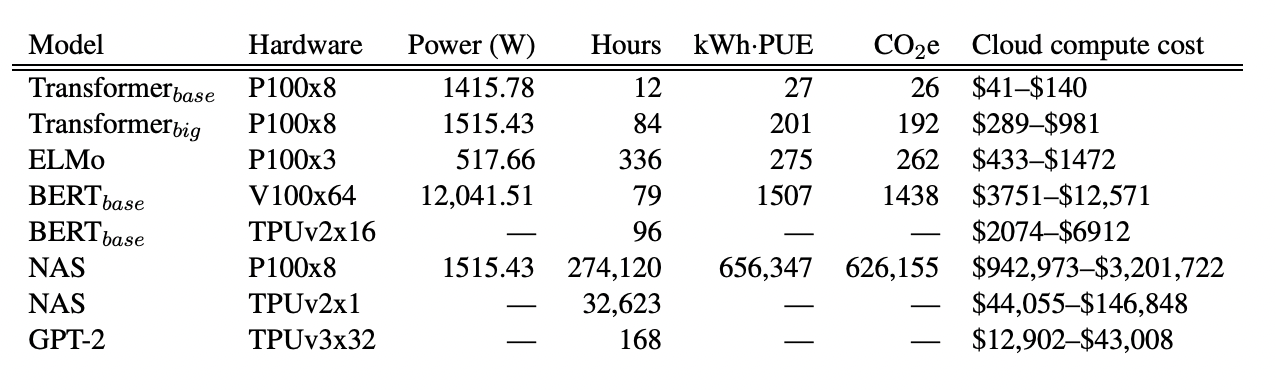
“Estimated cost of training a model in terms of CO2 emissions (lbs) and cloud compute cost (USD).7 Power and carbon footprint are omitted for TPUs due to lack of public information on power draw for this hardware.” (Source: Strubell, Ganesh, McCallum)
And, of course, as compute usage increases, so does the amount of electricity needed to conduct those calculations. As a result, the price continues to increase as well:

“Estimated cost in terms of cloud compute and electricity for training: (1) a single model (2) a single tune and (3) all models trained during R&D.” (Source: Strubell, Ganesh, McCallum)
🌴The environmental cost of training
That being said, companies are quick to the draw when it comes to combating claims of environmental negligence. For example, Meta argues in their 78-page paper on Llama-2:
100% of the emissions are directly offset by Meta’s sustainability program, and because we are openly releasing these models, the pretraining costs do not need to be incurred by others.
That is, they’re basically saying: Although training Llama-2 caused 539 tons of Carbon Dioxide equivalent (CO2eq) into the atmosphere, Meta’s internal environmental efforts compensated for those emissions; thus, Meta is helping the environment more than hurting it.
(And by the way, we read and did a breakdown of the entire 78-page Llama 2 paper. Check it out here. But you should totally read the original paper, though. It’s great.)
🍃 The end-to-end environmental cost analysis
Furthermore, in an analysis of Meta, a publication from MLSys 2022 notes that the breakdown of power capacity used in AI is 10:20:70 distributed over Experimentation, Training, and Inference, respectively. Furthermore, the energy footprint of the end-to-end machine learning pipeline is 31:29:40 over Data, Experimentation/Training, and Inference, respectively.
Basically, the carbon footprint of machine learning is non-zero, but also not as large as other industries. Of all the technological and innovative domains that produce a significant carbon footprint, machine learning is one that is relatively easy to offset—as Meta demonstrated with Llama-2 above.
Ultimately, these researchers hope that “the key messages and insights presented in this paper can inspire the community to advance the field of AI in an environmentally-responsible manner.”

A visualization of the power capacity breakdown and energy footprint analysis mentioned above. Click the image to see the full paper. (Source: Wu, et al.)
Whether those hopes will be fulfilled is a question yet to be addressed. In fact, a recent paper—which has picked up attention from reporters at Bloomberg and Fox—reveals that the AI industry might use more electricity than some small countries.
The graphic below illustrates just how much more energy-expensive AI is compared to a simple Google search. And if chatbots scale to become as consistently used as their search engine counterparts, we can only guess just how much the industry will spend on electricity in the upcoming years.

“Estimated energy consumption per request for various AI-powered systems compared to a standard Google search” (Source: de Vries, The growing energy footprint of artificial intelligence, Joule 2023)
Luckily, companies like HuggingFace are indeed making efforts to help the environment while also furthering technological progress. Sasha Luccioni, PhD, is the AI Researcher and Climate Lead at HuggingFace, whose job revolves around evaluating the environmental and societal impacts of AI models and datasets.
She and her team have made tremendous efforts to ensure that the interests of AI innovators and environmentalists alike, though sometimes at odds, never interfere or hinder one another.
Building on the success of my iceberg tweet, here is the full deck of my presentation about generative AI 👩💻: docs.google.com/presentation/d…
It talks about the history of AI, its planetary and human costs, and what its consequences can be. 🌎(1/3)— Sasha Luccioni, PhD 💻🌎🦋✨🤗 (@SashaMTL)
6:30 PM • Mar 27, 2023
🧑💻 Other Bits and Bytes
Evaluating LLMs is also a costly part of the industry. Below are three papers and a fantastically written Tweet thread on this oft-overlooked area of AI development. 💳️
🐯Evaluating LLMs is a minefield - In this annotated presentation, see what Princeton University has to say about evaluating LLMs and the difficulties with reproducibility in AI research. And with reproducibility comes increased costs.
👀Making AI fact-check itself actually works?! - This paper from Meta proposes a new method of avoiding AI hallucinations called Chain-of-Verification (CoVe). To see the four-step process, check out this paper.
📝But can AI correct its own logic as opposed to knowledge? - To play Devil’s Advocate to Meta above, researchers at Google DeepMind argue somewhat in contrast to Meta’s findings with CoVe: Large Language models cannot self correct reasoning yet
📊From Bindu Reddy CEO of Abacus AI: Techniques For LLMs to Verify Themselves And Reduce Mistakes
Techniques For LLMs to Verify Themselves And Reduce Mistakes
The single biggest reason we haven't seen too many LLM apps and agents in production is the LLMs either hallucinate or make mistakes.
The error rate is high enough that autonomous agents don't really work well for… twitter.com/i/web/status/1…
— Bindu Reddy (@bindureddy)
12:32 AM • Oct 14, 2023
🌟 Get up to $100,000 in speech-to-text credits.
Join the Deepgram Startup Program 🚀