- AI Minds Newsletter
- Posts
- Mining Massive Datasets: How experts (including you) can handle big data
Mining Massive Datasets: How experts (including you) can handle big data
Large datasets often take too long to sift through... until today. From Stanford to Berkeley, see how experts craftily organize big data into comprehensible chunks
Jose Nicholas Francisco & Marcel Santilli
January 25, 2024
Welcome (back) to AI Minds, a newsletter about the brainy and sometimes zany world of AI, brought to you by the Deepgram editorial team.
In this edition:
🎓 Stanford Course on Mining Massive Datasets
📊 How data will influence the future of ML
🐍 Python Topic Modeling with a BERT Model
📲 6 Trending AI Apps to check out!
⛏️ Exact Gaussian Processes for massive datasets
🧑🏫 Data mining in Action → Digital Marketing in Education
📕 Association Rules Mining with Auto-Encoders
🐦 Twitter on big datasets; where’s all this big data coming from?
🏓 Open-source, multimodal tabular deep learning via PyTorch
💰 Bonus Content: AI vs. Water, OSS vs. CSS, Text-to-Speech exposed
Thanks for letting us crash your inbox; let’s party. 🎉
Oh yeah, and while you may be familiar with Deepgram’s speech-to-text API, you might want to check out our upcoming text-to-speech technology as well 🥳

Exact Gaussian processes for massive datasets via non-stationary sparsity-discovering kernels: A Gaussian Process (GP) is a prominent mathematical framework for stochastic function approximation. However, GPs are inefficient, leading us to use approximations of GPs in practice. These GP approximations are limited in accuracy and flexibility. However, this paper argues that we can take advantage of natural sparsities in the datasets we try to model such that we can use exact GPs instead of approximate ones.
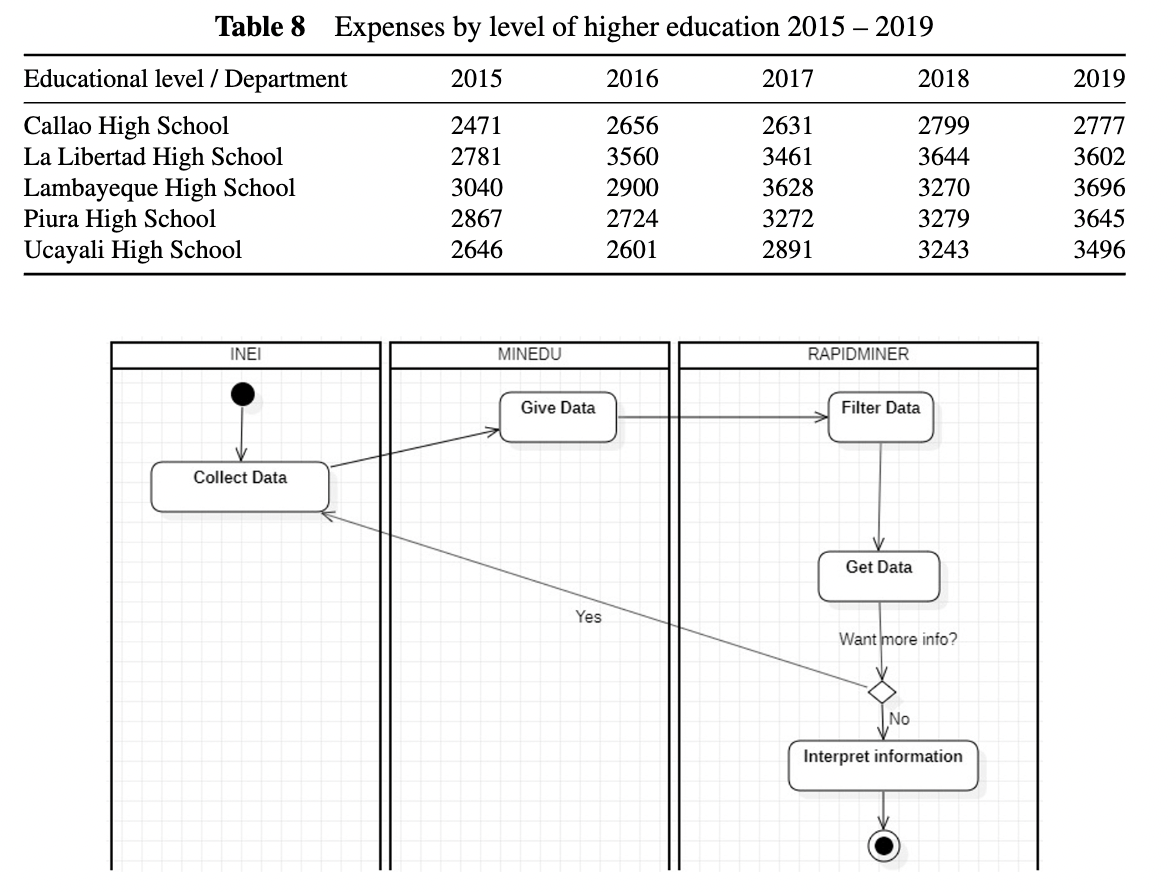
Data mining: Application of digital marketing in education: Curious what data mining looks like in practice? Check out this paper, in which the authors extract patterns from large datasets regarding education spending. From such data mining, the authors extracted a policy that educators and regulators can use going forward.

Association Rules Mining with Auto-Encoders: Association rule mining is one of the most studied research fields of data mining, with applications ranging from grocery basket problems to explainable classification systems. However, these algorithms are often inefficient. To ameliorate this issue, this paper presents an auto-encoder solution to mine association rule called ARM-AE. Find out more within!
🧭 Trending AI Apps to Check Out!
Have you seen our piece of the internet dedicated to showing off AI Apps? Here are the top 5 trending apps over the past week.
HomeWorkify - Get homework answers in seconds with AI-powered Q&A search engine.
Toma - An AI voice platform designed to automate both inbound and outbound business calls
Chatgot - The AI conversation hub bringing together diverse bots for engaging interactions.
ChatGPR - Captivate audiences with AI-generated social media content.
StarByFace - Discover which celebrity you look like with facial recognition technology.
Caricaturer - Turn photos into exaggerated caricatures.
🏇 The Big Deal with Big Data

The Mining of Massive Datasets - The title of this edition of AI Minds is based on a course from Stanford University called “Mining Massive Datasets.” Jure Leskovec, Anand Rajaraman, Jeff Ullman—who own and teach the course—host this website, which comes loaded with algorithms, pseudocode, and code for mining datasets all available for free!

How data will influence the future of ML- In this episode of “The AI Show,” Scott and Susan discuss how large datasets come to be and why they’re useful. Read the article in the link above, or watch the episode here!

Python Topic Modeling with a BERT Model- This link will take you to a section of a larger Python tutorial. The section the link leads to showcases a real-life example of dataset exploration—specifically a dataset on Topic Modeling. Here, we offer a practical application to the techniques described in the websites above.
🎥 Lecture Series: Mining Massive Datasets (Stanford CS246)
As mentioned earlier, the title of this edition of AI minds is based off of Stanford’s class “CS 246: Mining Massive Data Sets.” As a result, we can’t not showcase the lecture itself. So here it is! Take a Stanford AI class through the playlist linked above.
Editor’s Note: One of the authors of AI Minds (Jose Francisco) actually took this class in 2022! He says it was one of the most useful and applicable courses he took while at Stanford.
700-page PDF — #Algorithms for Decision-Making — download brilliant & comprehensive FREE eBook from MIT: bit.ly/3wyNcnQ
—————
#AI#MachineLearning#BigData#DataScience#DataScientists#Mathematics#Statistics#DecisionScience#DataLeadership#AnalyticsStrategy— Kirk Borne (@KirkDBorne)
12:29 AM • Jan 22, 2024
Know where your AI’s getting their data from?
This is great initiative: Fairly Trained, by @ednewtonrex and others, to certify whether AI data are fairly sourced.
— Gary Marcus (@GaryMarcus)
3:08 PM • Jan 22, 2024
🚀🎉 Excited to announce 🌟 PyTorch Frame 🌟 - our new open-source initiative in PyTorch! Dive into multi-modal tabular deep learning like never before!
Link: github.com/pyg-team/pytor…
#PyTorch#OpenSource (1/6)
— Weihua Hu (@weihua916)
10:22 AM • Dec 18, 2023
🤖 Additional Bits and Bytes

How AI Consumes Water: The unspoken environmental footprint - When discussing the intersection of machine learning and the environment, AI’s carbon footprint often takes the spotlight. But what about its water footprint? To learn just how much water goes into AI—from cooling systems to server manufacturing—check out this article!

Battle of the Models: Open-Source vs. Closed-Source in AI Applications! - In this article, Nithanth compares and contrasts the experience of building an app with open-source AI versus closed-source AI models. Which one comes with better resources? Which one is easier to use? Who’s documentation is less of a hassle to navigate? Find out within 👀

Challenging LLMs: An in-depth look at Text-to-Speech AI - A sneak peek at an upcoming edition of AI Minds! In this article, Andy Wang takes a look at the challenges of text-to-speech AI, from the rise of transformers to prosody issues. If you’ve ever wondered just how difficult it is to make a robot sound like a human, this article is for you!
🐝 Social media buzz